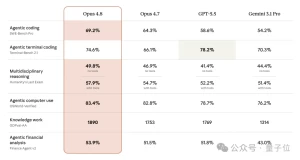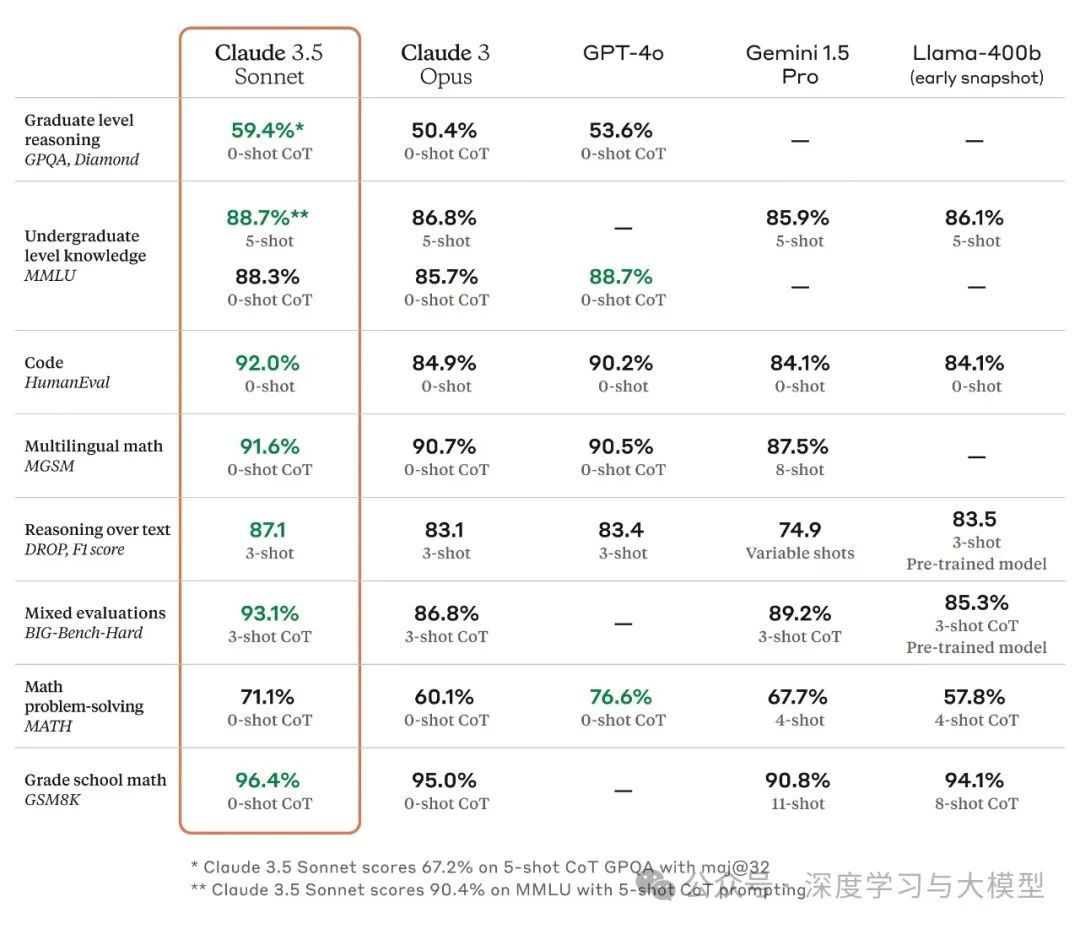
研究生水平推理 (GPQA, Diamond): Claude 3.5 在 0-shot CoT 设置下取得了 59.4% 的准确率,略高于 GPT-40 的 53.6%。这表明 Claude 3.5 在处理复杂推理问题方面具有优势。 本科水平知识 (MMLU): Claude 3.5 在 5-shot 设置下取得了 88.7% 的准确率,与 GPT-40 相同,略高于 Gemini 1.5 Pro 和 Llama-400b。这表明 Claude 3.5 拥有丰富的知识储备,能够应对各种学科的知识问题。 代码生成 (HumanEval): Claude 3.5 在 0-shot 设置下取得了 92.0% 的准确率,领先于其他模型。这表明 Claude 3.5 在代码生成方面具有较强的能力,能够理解代码逻辑并生成高质量的代码。 多语言数学 (MGSM): Claude 3.5 在 0-shot CoT 设置下取得了 91.6% 的准确率,略高于 GPT-40 和 Gemini 1.5 Pro。这表明 Claude 3.5 能够理解和解决不同语言的数学问题。 文本推理 (DROP, F1 score): Claude 3.5 在 3-shot 设置下取得了 87.1 的 F1 score,领先于其他模型。这表明 Claude 3.5 能够理解文本内容,并进行复杂的推理以回答问题。 混合评估 (BIG-Bench-Hard): Claude 3.5 在 3-shot CoT 设置下取得了 93.1% 的准确率,领先于其他模型。这表明 Claude 3.5 能够应对各种类型的任务,并展现出强大的适应能力。 数学问题解决 (MATH): Claude 3.5 在 0-shot CoT 设置下取得了 71.1% 的准确率,略高于 GPT-40,但低于 Gemini 1.5 Pro。这表明 Claude 3.5 在解决数学问题方面具有潜力,但仍有提升空间。 小学数学 (GSM8K): Claude 3.5 在 0-shot CoT 设置下取得了 96.4% 的准确率,领先于其他模型。这表明 Claude 3.5 能够轻松解决小学数学问题。
CoT 指的是"Chain-of-Thought",中文翻译为 思维链。思维链 (CoT) 是一种提示工程技术,用于增强语言模型的推理能力。它通过向模型提供一系列中间步骤来解决问题,而不是直接给出答案。0-shot CoT 指的是 不使用任何示例 来训练模型进行思维链推理。模型需要从零开始,自己推导出解决问题的步骤。5-shot CoT 指的是 使用 5 个示例 来训练模型进行思维链推理。模型通过学习这些示例中的推理步骤,能够更好地理解如何解决类似的问题。简而言之,0-shot CoT 就是让模型在没有任何示例的情况下,仅凭一次提示就能理解任务并尝试解决问题。包含了几个关键点:
没有训练数据:模型没有事先学习过任何与任务相关的示例。
一次 prompt:模型只接受一次提示,没有其他信息。
理解任务:模型需要根据提示理解要完成的任务。
尝试解决:模型需要根据理解的任务尝试给出答案。
0-shot CoT 的评估结果可以反映模型在没有先验知识的情况下进行推理和解决问题的能力。它通常用于测试模型的泛化能力,以及模型对新任务的学习能力。"5-shot" 和 "8-shot" 也都是代表在训练模型时提供的示例数量
4)Reasoning over text (DROP, F1 score)
Reasoning over text: 指的是语言模型需要理解文本内容,并根据文本信息进行推理,得出结论或回答问题。
DROP: 指的是一个名为 "DROP" Discrete Reasoning over Paragraphs的数据集,它包含了大量的问答对,这些问答对需要模型进行文本推理才能回答。DROP 数据集的特点是需要模型进行复杂的推理,例如从多个句子中提取信息、进行算术运算、理解时间关系等。
F1 score: 指的是一种评估模型性能的指标,它衡量了模型预测结果与真实结果之间的匹配程度。F1 score 的值介于 0 到 1 之间,数值越高表示模型的性能越好。
计算方法为:F1 score = 2 * (Precision * Recall) / (Precision + Recall) 其中的Precision是模型预测为正例的数量除以模型预测为正例的总数。Recall是模型预测为正例的数量除以真实为正例的总数。
本文链接:https://ki4.cc/Claude/65.html
Claude3和GPT4claudeai如何注册claude官网手机版下载claude2官网免费版claude官网免费claude公司官网claude ai官网地址claude官网注册claude官网网址claude 2官网