最近一直在出差和开会,没能及时跟进最新的AI动态。今天,试用了已经火了一段时间的Claude 3。
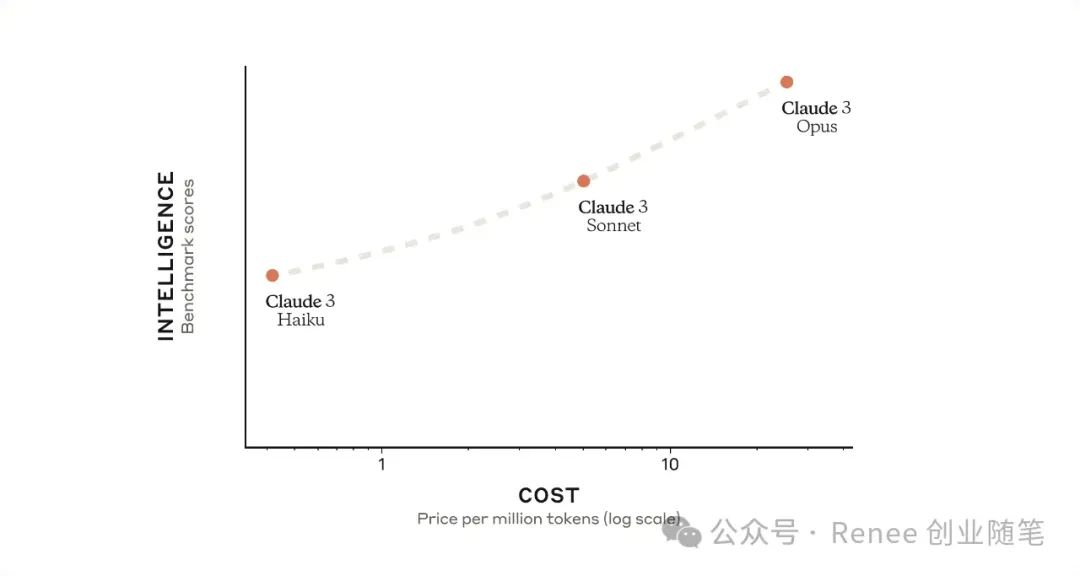
Claude 3在2024年3月4日发布的。Claude 3包含三个模型:Claude 3 Haiku、Claude 3 Sonnet和Claude 3 Opus,能力递增。
| 功能/模型 | Opus | Sonnet | Haiku |
|---|---|---|---|
| 描述 | 最智能的模型,在高度复杂任务上的性能是市场上最好的 | 实现了智能与速度之间的理想平衡,特别是对于企业工作负载 | 最快速、最紧凑的模型,能够提供近乎即时的响应性 |
| 输入成本价格 /million tokens | $15 | $3 | $0.25 |
| 输出成本价格 /million tokens | $75 | $15 | $1.25 |
| 上下文窗口 tokens | 200K,同时针对特定用例提供1M | 200K | 200K |
| 潜在应用 | 任务自动化、研发、策略 | 数据处理、销售、节省时间的任务 | 客户互动、内容审核、节省成本的任务 |
| 特点 | 提供市场上其他所有模型都无法比拟的高智能 | 相比其他类似智能的模型更经济,更适合大规模应用 | 在其智能类别中更聪明、更快速、更经济 |
| 前端页面使用 | Claude.ai Pro 订阅者 | claude.ai 免费用户 | 马上上线 |
| API 调用 | 支持 | 支持 | 马上上线 |
| 第三方云平台支持 | AWS Bedrock/Google Vertex AI Model Garden | 马上上线 | 马上上线 |
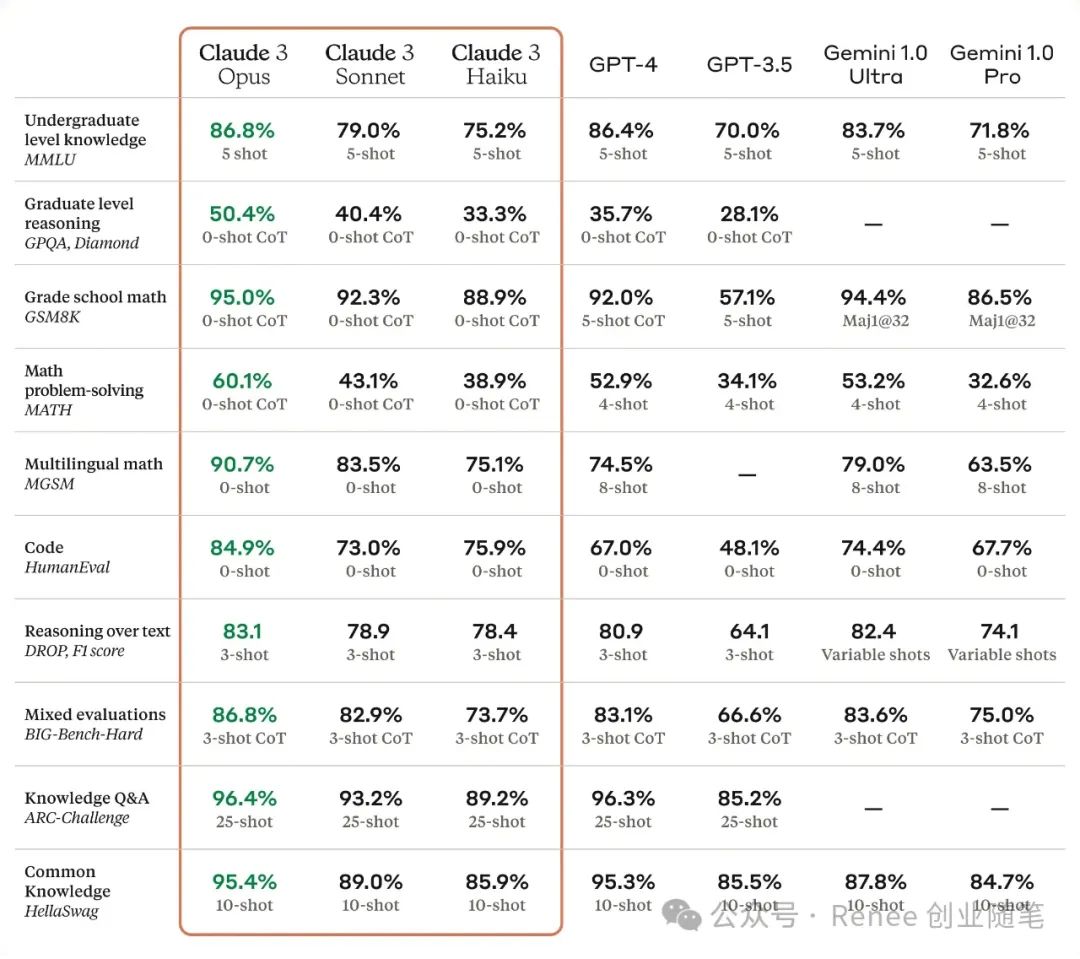
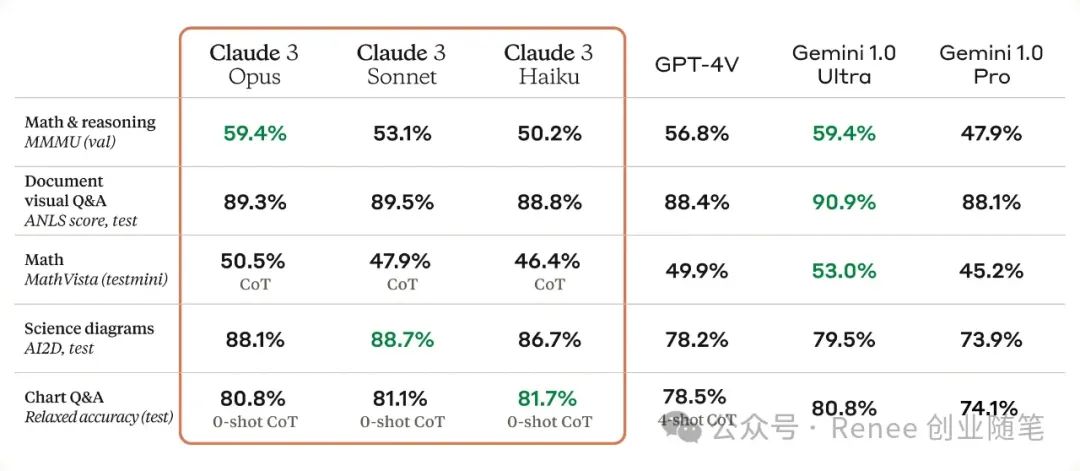
多个能力基准测试比较
评估包括本科级专家知识(MMLU)、研究生级专家推理(GPQA)、基础数学(GSM8K)等。
Claude 3 Opus在复杂任务上展现出接近人类的理解和流畅度。所有Claude 3模型在分析和预测、细腻的内容创作、代码生成,以及使用西班牙语、日语和法语等非英语语言进行交流方面的能力都有所增强。
推理速度
Claude 3模型能够支持实时的客户聊天、自动补全和数据提取任务,这些任务需要即时和实时的响应。
Haiku是市场上同类智能模型中最快速和最具成本效益的。它能在不到三秒的时间内阅读一个信息和数据密集的arXiv研究论文(约10000个Token)及其图表和图形。随着产品的推出,预计性能将进一步提升。
对于大多数工作负载而言,Sonnet的速度是Claude 2和Claude 2.1的两倍,而且智能水平更高。擅长需要快速响应的任务,如知识检索或销售自动化。
Opus的速度与Claude 2和2.1相似,但智能水平要高得多。
视觉能力比较
Claude 3模型具有与其他领先模型相当的复杂视觉能力。它们能够处理各种视觉格式,包括照片、图表、图形和技术图解。可以理解各种格式编码,如PDF、流程图或演示幻灯片的知识库。
肉眼可见的聪明
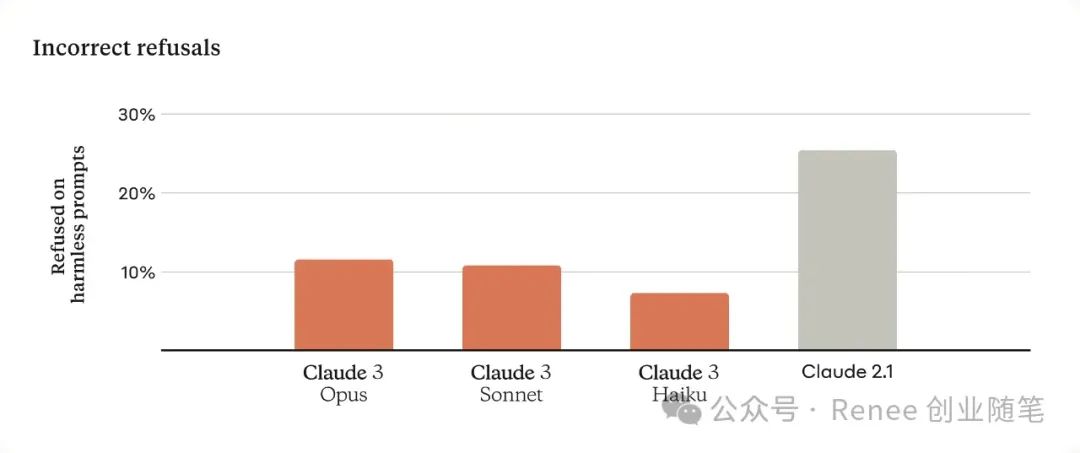
以往的Claude模型经常做出不必要的拒绝回应,这暗示了对上下文的理解不足。相比下,Opus、Sonnet和Haiku在接近系统安全边界的提示上拒绝回答的可能性大大降低。如下所示,Claude 3模型对请求展现了更加细腻的理解,能够识别真正的危害,并且在面对无害的提示时较少拒绝回答。
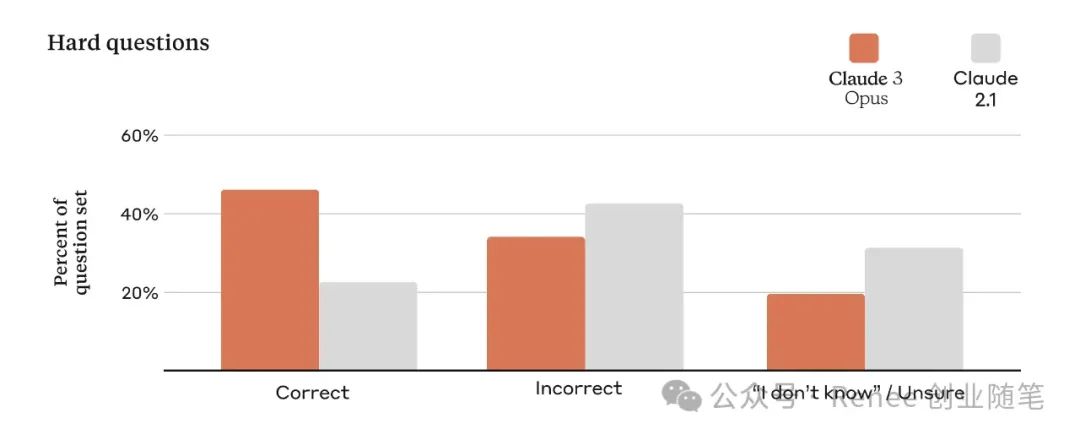
将回答分为正确答案、错误答案(或幻觉)和不确定性承认,其中,不确定性承认是指模型声明它不知道答案,而不是提供错误信息。与Claude 2.1相比,Opus在这些具有挑战性的开放式问题上展现了两倍的准确性改进(或正确答案),同时还显示出减少的错误答案水平。除了产生更可信的回应之外,很快还将在Claude 3模型中启用引用功能,使它们能够指向参考材料中的确切句子来验证其答案。
上下文窗口
Claude 3系列模型在初次发布时提供20万个上下文窗口。然而,所有三个模型都能够接受超过100万个token的输入,可能会向需要增强处理能力的特定客户提供这一功能。
为了有效处理长上下文提示,模型需要强大的回忆能力。Claude 3采用了大海捞针'(NIAH)来进行评估。NIAH,或“大海捞针”(Needle In A Haystack),是一个评估模型的能力,特别是在从大量数据中准确提取特定信息的能力。在人工智能和机器学习领域,这种评估通常用于测试模型能否有效地从庞大、复杂的数据集中检索出极为细微或特定的信息片段。
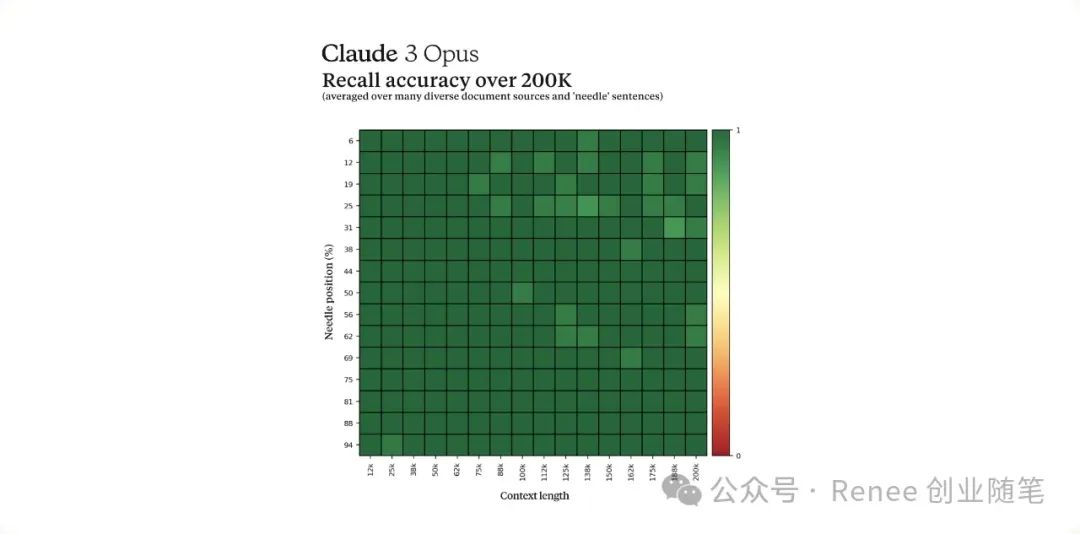
通过使用每个提示中的30个随机针/问题对之一,并在一个多样化的众包文档语料库上测试,增强了这一基准测试的稳健性。Claude 3 Opus不仅实现了近乎完美的回忆,准确率超过了99%,而且在某些情况下,它甚至识别了评估本身的局限性,认识到“针”句似乎是人为插入到原始文本中的。
安全和隐私
设有多个专门团队来追踪和减轻广泛的风险,包括错误信息、儿童色情材料(CSAM)、生物误用、选举干预和自主复制技能。团队还在继续开发如宪法式AI等方法,以提高模型的安全性和透明度,并已调整我们的模型以减轻新模态可能引发的隐私问题。如模型卡片所示,根据问题回答偏见基准测试(BBQ),Claude 3模型显示的偏见少于之前的模型。团队致力于推进减少偏见和促进模型更大中立性的技术,确保它们不偏向任何特定的政治立场。
虽然Claude 3模型家族在生物学知识、网络相关知识和自主性方面相比以往模型有所进步,但根据负责任扩展政策,它仍处于AI安全级别2(ASL-2)。红队评估(按照团队对白宫的承诺和2023年美国行政命令进行)已得出结论,模型目前的灾难性风险潜力可以忽略不计。我们将继续仔细监控未来的模型,评估它们与ASL-3阈值的接近程度。
易于使用
Claude 3模型更擅长遵循复杂的多步骤指令。特别擅长坚持品牌声音和响应指南,此外,Claude 3模型在生成像JSON这样流行的结构化输出方面表现更佳——使得指导Claude用于自然语言分类和情感分析等用例变得更简单。
未来展望
Anthropic 团队认为模型智能远未触及其极限,并计划在接下来的几个月中频繁更新Claude 3模型家族。还计划发布一系列功能以增强模型的能力,特别是针对企业用例和大规模部署。这些新功能将包括工具使用(function calling)、交互式编程(REPL)和更高级的代理能力(agent)。
明天会分享一些Claude 3的实用案例分析。
本文链接:https://ki4.cc/Claude/10.html
ClaudeClaude价格Claude3和GPT4Claude官网入口GPT4Claude opusOpenAIGPT-4Anthropic