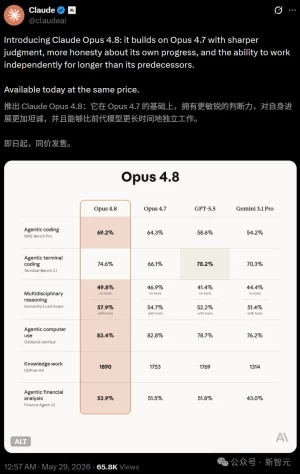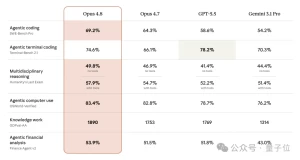
▊ 前言
导读
在人类社会中,裙带关系或偏袒行为常被视为不公正的,但在人工智能的世界里,情况会怎样呢?
通常下我们认为机器应该更加公正、客观。然而,最新研究揭示了一种令人惊讶的现象:当AI模型扮演评判角色时,它们似乎也会“偏爱”与自己“血脉相连”的其他AI模型。这种发现挑战了我们对于人工智能绝对公正性的传统看法,也为AI的评测标准带来了新的挑战。
本文将深入探讨 LMSYS 最新发布的研究,该研究涉及使用两大AI模型——GPT-4 Turbo 和 Claude 3 Opus——作为评委来评估其他AI的性能。研究结果显示,这些AI评委在评分时表现出了显著的内部偏好,即每种AI倾向于给予与自己技术架构相似的模型更高的评分。例如,当GPT-4作为评委时,OpenAI系列的模型通常会获得较高分数;而当评委换成Claude 3时,情况则大为不同,Anthropic系列模型的得分更为突出。
这种内部偏好现象引发了关于AI评价系统公正性的重要讨论。在设计和部署AI系统时,我们如何确保这些智能系统评估的公平性和透明度?本文将揭示这些智能系统背后的“同类”倾向性如何潜在影响技术的客观性和公正性,以及我们应如何应对这一挑战。
背景信息
当地时间2024年4月19日LMSYS Org平台发布了一篇文章:《从实时数据到高品质基准:Arena-Hard 数据流水线》,它详细阐述了如何利用从 Chatbot Arena 众包平台收集的实时数据构建一个名为“Arena-Hard”的新型LLM(大语言模型)性能基准测试系统。
文章摘要
文章主要介绍了Arena-Hard基准测试系统的开发和实现,其目的是为LLM提供一个更为动态、实用且频繁更新的性能评估工具。与传统的静态或封闭式基准测试不同,Arena-Hard旨在通过使用实时数据来生成测试内容,从而更准确地反映LLM在实际应用中的性能。文中讨论了基准测试的关键指标,包括与人类偏好的一致性和模型间的分离能力,并通过与现有基准MT Bench的比较来突出Arena-Hard的优势。
重要观点
1.高分离性与人类偏好的一致性:Arena-Hard在确保基准测试与人类偏好高度一致的同时,也能有效分辨不同LLM的能力,显示出较其他基准如MT Bench更高的性能。
2.动态更新机制:与传统基准测试通常使用静态数据不同,Arena-Hard采用实时更新的数据集,从而避免了过度拟合和测试集泄漏的问题,保证了测试结果的新鲜度和有效性。
3.基于实时用户数据的提示生成:通过对Chatbot Arena平台上真实用户互动的分析,Arena-Hard可以生成覆盖广泛主题的高质量提示,这些提示更能反映出LLM在真实世界应用中的表现。
意义和价值
评估和比较LLM的工具:AI爱好者和开发者可以使用Arena-Hard作为一个强大的工具来评估和比较不同的LLM性能,特别是在开发过程中调整和优化模型。
深入了解LLM性能评估的最新方法:文章介绍了构建现代基准测试的新方法和技术,这对于那些对AI技术持续追踪并希望保持最新的人来说,提供了宝贵的知识和见解。
启发新的研究和开发:通过分析Arena-Hard的构建过程和它的优势,AI爱好者可能会受到启发,开发出更多创新的AI应用和评估方法,特别是在处理实时数据和应对快速变化的AI领域中。
总之,这篇文章不仅为AI研究和开发社区提供了一个强大的新工具,也促进了对LLM在实际应用中表现的深入理解和评价,为AI技术的进步和应用提供了重要支持。
说明:原文来自:https://lmsys.org/blog/2024-04-19-arena-hard/。翻译则由GPT应用:“科技文章翻译”完成。前言部分由GPT-4输出,经我完善而成。Arena-Hard简单说就是一个评测大模型性能的工具,LMSYS 平台也将其Github项目公布出来了,若你是开发者也可以使用该工具评测国内的大模型。下文中的链接部分可阅读原文获取。
▊ 从实时数据到高品质基准:Arena-Hard 数据流水线
作者: Tianle Li*, Wei-Lin Chiang*, Evan Frick, Lisa Dunlap, Banghua Zhu, Joseph E. Gonzalez, Ion Stoica, 2024年4月19日
为LLM聊天机器人构建一个既经济又可靠的性能基准已成为当前的一项挑战。一个优质的基准需要具备以下几个特点:
1.能够明确区分不同模型的能力;
2.能反映出真实场景下用户的偏好;
3.需要频繁更新,以避免过拟合或数据泄露。
传统的基准测试往往是静态的或闭环的(例如,MMLU多项选择题),不能满足上述需求。同时,模型的迭代速度空前,加剧了制定能有效区分性能的基准测试的必要性。
本文介绍了Arena-Hard,一个能够从Chatbot Arena的实时数据中生成高质量基准的数据流水线。Chatbot Arena 是一个众包平台,用于评估LLM的表现。为了评估其质量,我们设定了两个关键指标:
1.与人类偏好的一致性:基准得分是否与人类偏好高度一致。
2.分离能力:基准是否能够确信地区分不同的模型。
我们将新的基准Arena Hard v0.1与当前领先的聊天LLM基准MT Bench进行了比较。
如图1所示,Arena Hard v0.1在模型分离能力上显著优于MT Bench,其置信区间也更为紧凑。它在与Chatbot Arena(只限英语)的人类偏好排名上也显示出更高的一致性(89.1%,见表1)。我们预期这一基准能帮助模型开发者更好地区分他们的模型版本。
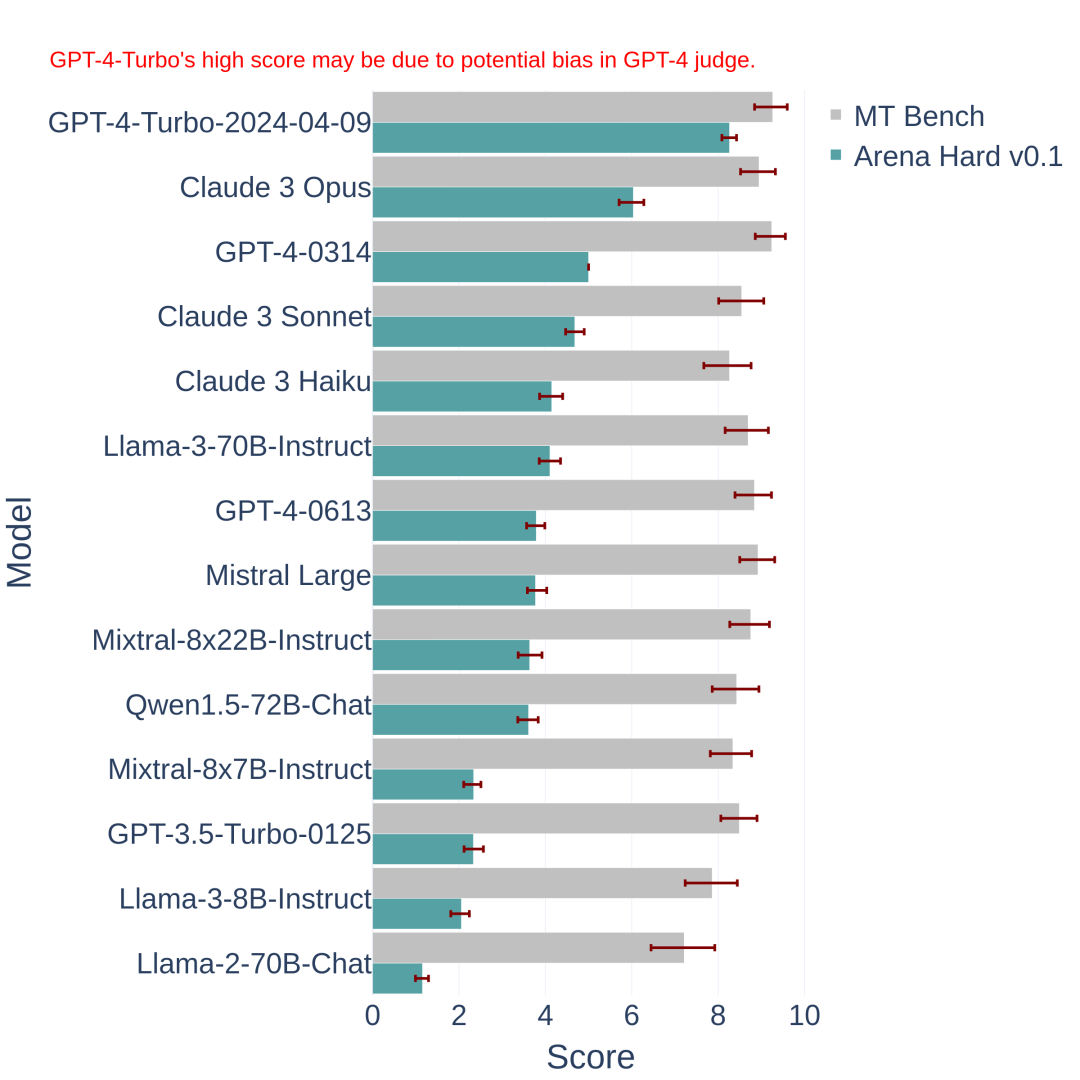
图1:MT-bench与Arena Hard v0.1的比较。后者在模型间的分离能力和置信区间方面表现得更好。GPT-4-0314在Arena-hard-v0.1中表现稳定,因为它作为基准模型使用。
链接:
在Arena-Hard-v0.1上测试您的模型:链接。
探索Arena-Hard-v0.1的提示库:链接。
Google Colab中的统计笔记本:链接。
在结果部分查看完整排名:跳转。
在以下部分,我们将详细解释更多技术细节。
LLM基准的关键目标
我们概述了一个理想的LLM聊天机器人基准应具备的几个关键属性,这些属性可以有效地衡量不同模型之间的能力差异:
1.与人类偏好的一致性:它应当能够反映出真实使用场景中用户的偏好。
2.分离能力:它应提供可靠的置信区间,以确信地区分不同模型。
3.新鲜度:应使用全新、未曝光的测试用例,以防潜在的数据泄露。
我们通过以下方式定义一致性:对于一个给定的模型对(若B能够准确区分)
如果A能够确信地区分这两个模型
+1.0 表示与B的排名顺序一致。
-1.0 表示与B的排名顺序不一致。
+0.0 表示A无法确信地区分这两个模型
一致性得分为1意味着基准A在每一对独特模型的偏好上都表现出确信的一致性。相反,一致性得分为-1则意味着基准B在每一对独特模型的偏好上都表现出确信的不一致。
我们通过基准是否能够通过派生的置信区间确信地区分模型对来定义分离能力。这个指标还可以用来衡量基准所提供的排名结果的变异性。我们通过不重叠的置信区间占比来量化这一指标。
我们使用一组在Chatbot Arena(2024年4月13日)上表现优异的前20名模型,这些模型也出现在AlpacaEval排行榜上,来评估每个基准的分离能力和一致性。我们以Chatbot Arena的人类偏好排名(仅限英语)作为一致性评估的基准。
在表1中,Arena-hard-v0.1在分离能力上表现最佳(87.4%),在与Chatbot Arena的一致性上也达到最高(89.1%),同时成本低廉,反应迅速(25美元)。
有趣的是,我们发现Spearman相关系数这一流行的排名相关性度量可能不够可靠,因为它没有考虑排名的方差,因此不能有效地惩罚我们最关心的顶级模型的关键排名细节。例如,当考虑到95%的置信区间时,MT-bench与Chatbot Arena的一致性从91.3%降至22.6%。
您可以在结果部分找到完整的统计数据。
表 1. 每个基准的分离性和一致性
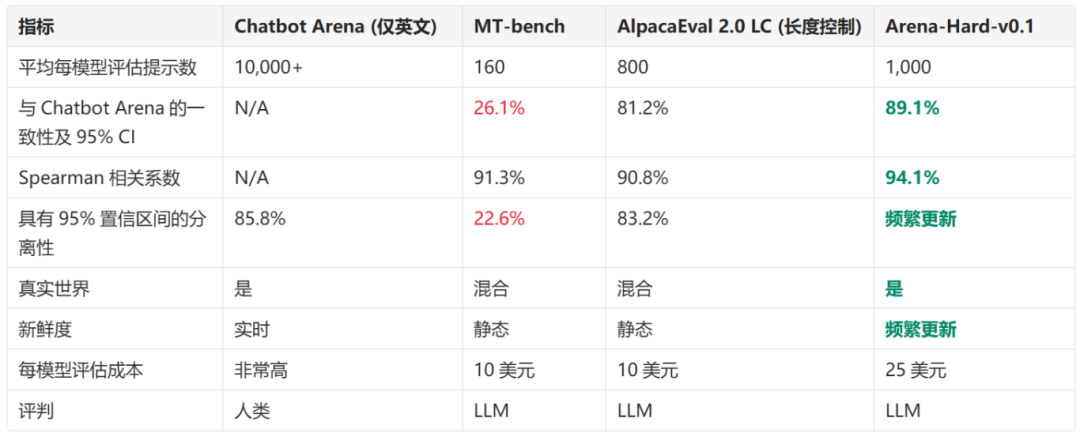
*结果基于从Chatbot Arena的前20名模型中随机挑选,这些模型也出现在Alpaca Eval排名中。
接下来,我们将详细阐述如何构建用于确保数据质量的提示选择流水线。
Arena-Hard 流水线
我们构建了一个自动从 Chatbot Arena 收集的 200,000 个用户查询数据集中提取高质量提示的流水线。此过程包括确保:
多样性:提示集应涵盖广泛的实际主题。
提示质量:每个提示应具有足够的质量,以便为 LLM 提供基准测试。我们在下文(见表 2)定义了几个关键标准。
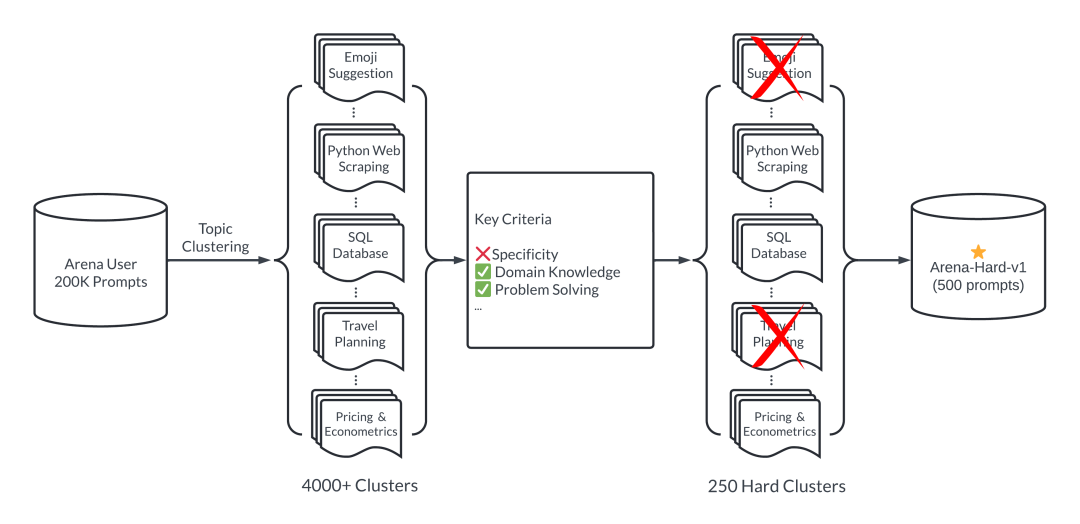
图 2:Arena-Hard 流水线
为了确保提示的多样性,我们采用了 BERTopic中的主题建模流水线,通过 OpenAI 的嵌入(text-embedding-3-small)转换每个提示,使用 UMAP 进行降维,并应用基于层次的聚类算法(HDBSCAN)来识别聚类,这些聚类随后由 GPT-4-turbo 概括。这有助于我们识别覆盖广泛领域的 4000 多个主题。然而,主题聚类在基准测试 LLMs 时具有不同的质量和分离能力。我们随后开发了一个定制的系统提示,以帮助我们选择高质量用户查询。以下是七个关键标准:

LLM 评委(如 GPT-3.5-Turbo、GPT-4-Turbo)对每个提示进行评分,从 0 到 7 表示满足的标准数量。然后我们根据其提示的平均分数对每个聚类进行评分。以下,我们展示了从低到高平均分数的主题聚类示例。通常,得分较高的聚类与对 LLMs 构成挑战的主题或任务相关,如游戏开发或数学证明;而得分较低的聚类则倾向于涉及较为琐碎或含糊的问题,如“设计风格和影响”。
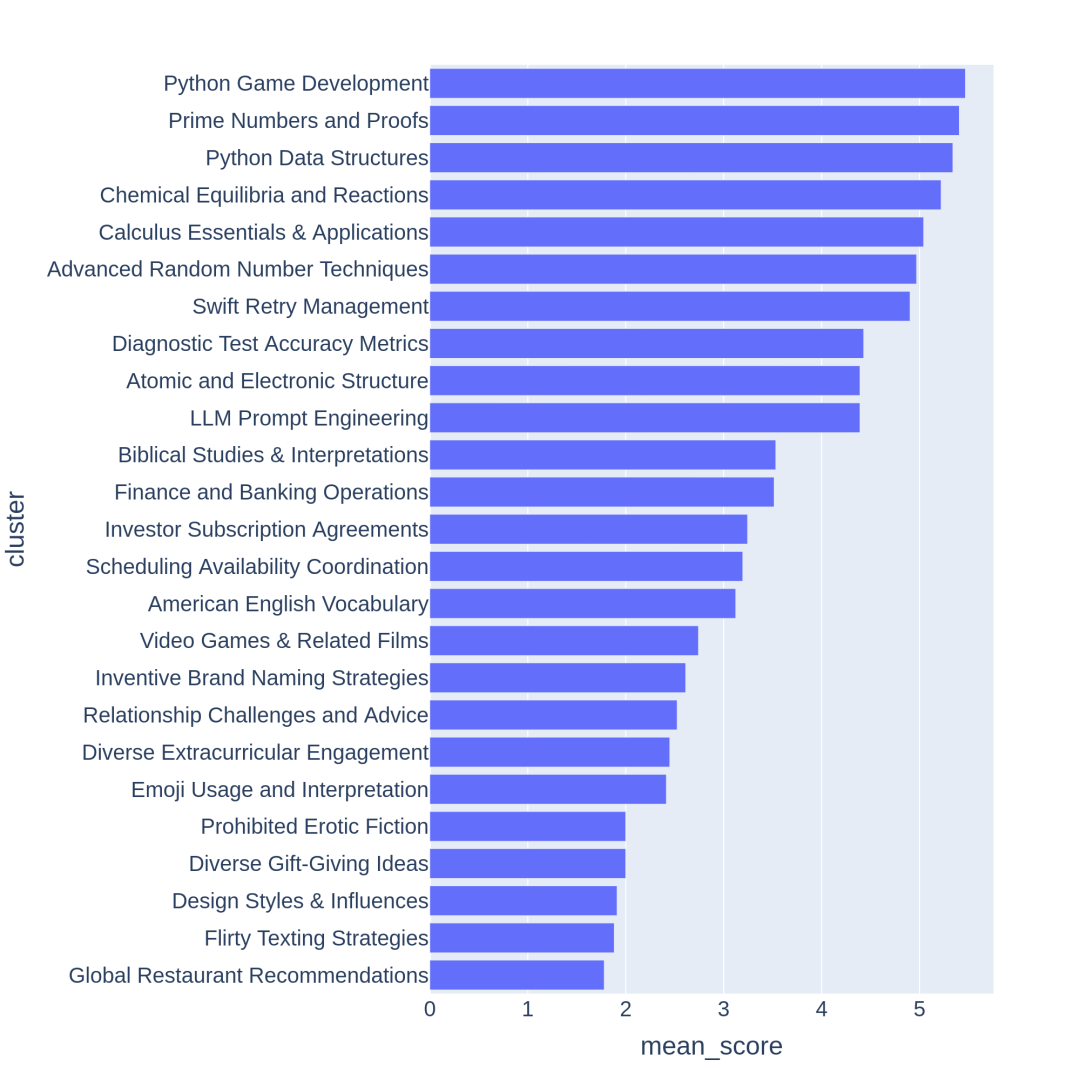
图 3:根据得分排序的 Chatbot Arena 聚类。
为了查看提示得分是否与分离能力相关,我们针对每个得分级别抽取 50 个提示,并比较 GPT-4 和 Llama-70b 的响应,由 GPT-4-Turbo 作为评判。我们观察到高得分的提示与 GPT-4 胜过 Llama-70b 的胜率之间存在强相关性。在其他模型对比中,如 Claude Sonnet 对抗 Haiku 和 Mistral-large 对抗 Mixtral,也观察到了类似的趋势。
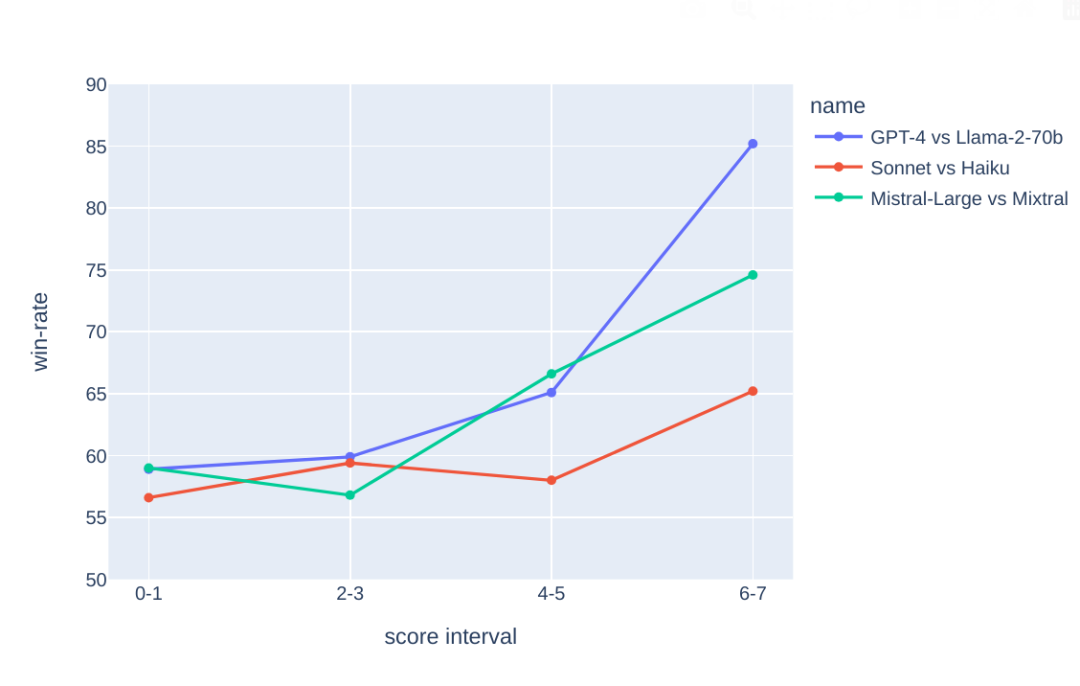
图 4:随着“7 关键标准”得分的增加,模型对之间的胜率变得更加明显。
▊ 结果
Arena-Hard-v0.1 作为评委
利用上述流水线,我们确定了 250 个平均分数≥6 的高质量主题聚类。然后我们随机从每个聚类中抽取 2 个提示,构建出 500 个高质量基准提示,即 Arena-Hard-v0.1。这套基准集主要包含定义明确、需要技术性问题解决技能的查询,符合上述关键标准。您可以通过此链接浏览所有提示。
然而,对如 Arena-Hard-v0.1 这样的挑战性查询进行模型评估并非易事。大多数查询涉及深入的领域知识和问题解决技巧,需要专家级判断来评估答案质量。不幸的是,这既昂贵又耗时。遵循 LLM 作为评委和 AlpacaFarm 的做法,我们采用 LLM 作为评委框架来近似人类偏好。
我们采用成对比较设置,针对一个强基线模型(GPT-4-0314),并要求一个强评委模型(例如 GPT-4-Turbo 或 Claude-3-Opus)将偏好分类为五个级别:A >> B, A > B, A~=B, .. B>>A。这种方式,模型在大的损失中会受到更严格的惩罚,这在分离模型时被证明是有效的。我们还采用链式推理(Chain of Thought, CoT)来引导 LLM 评委首先生成答案,然后再作出判断。完整的评委配置可以在这里找到。
为了避免潜在的位置偏见,我们采用双游戏设置——对每个查询,我们交换模型在第一和第二位置。这导致每个模型评估进行 1000x2=1000 次判断。遵循 Chatbot Arena 的做法,我们采用 Bradley-Terry 模型来产生模型的最终分数。通过从所有模型中引导比较,我们发现这种方法在统计上是稳定的,与仅考虑对基线模型的胜率相比更为可靠。
GPT-4-Turbo 作为评委
我们使用 gpt-4-1106-preview 作为评委模型来生成模型响应对基线的判断。我们采集所有比较并计算每个模型的 Bradley-Terry 系数。然后我们将其转换为对基线的最终分数。95% 置信区间是通过 100 轮引导计算的。
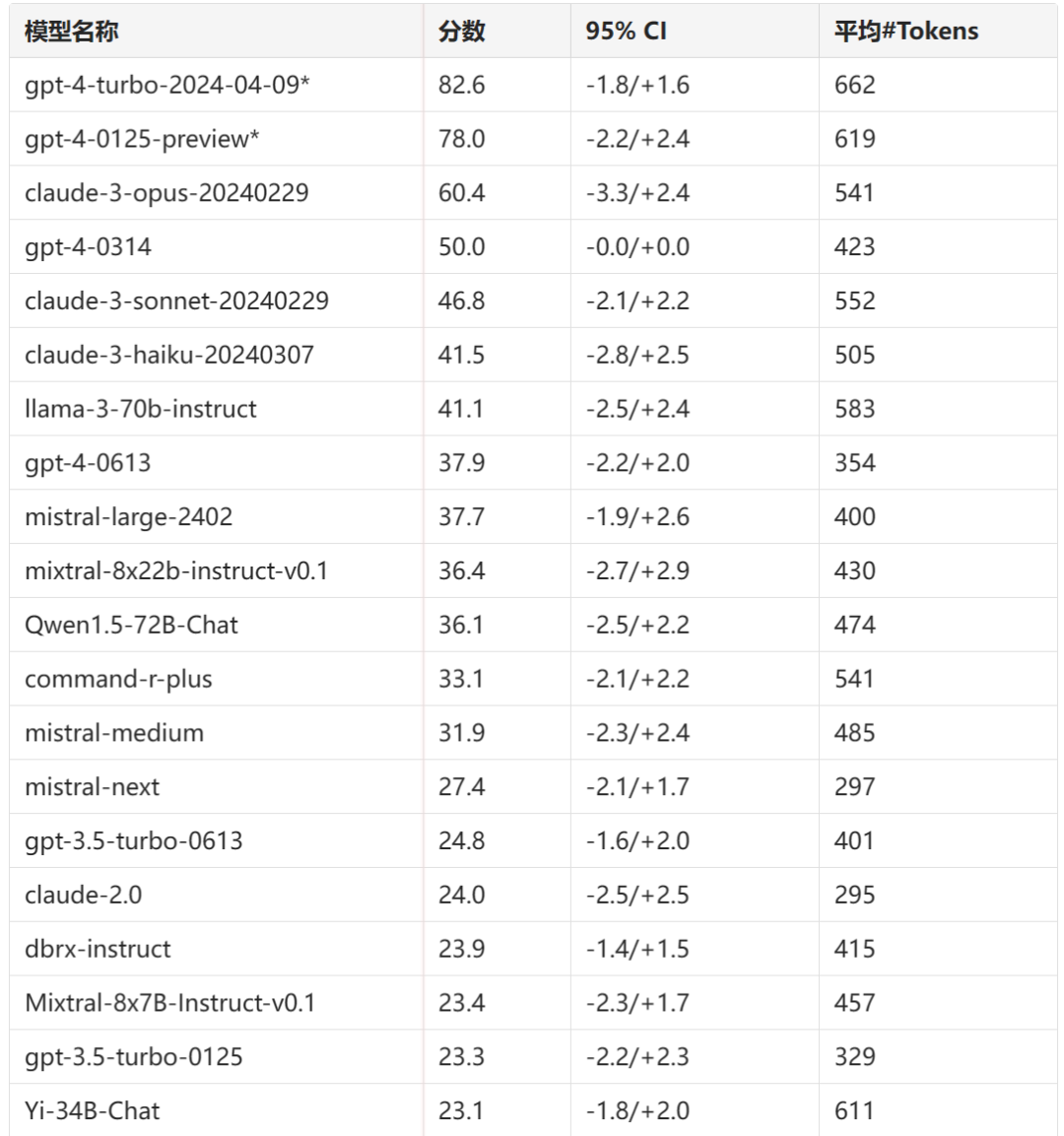
Arena Hard v0.1 排名(基线:GPT-4-0314)
*注意:GPT-4-Turbo 的高分可能是由于 GPT-4 评委偏好 GPT-4 输出。
GPT-4-Turbo 或 Claude 作为评委
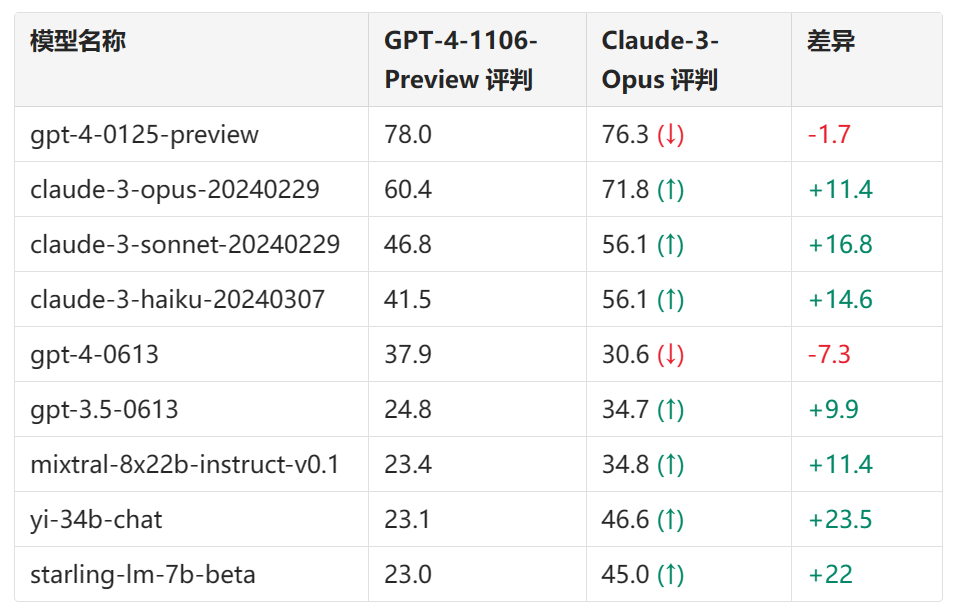
我们还比较了两个最强的 LLMs:GPT-4-1106-Preview 和 Claude-3 Opus 作为评委模式。使用 GPT-4 评委时,我们观察到模型间的分离性更高(范围从 23.0 到 78.0)。使用 Claude 评委时,我们发现 Claude 系列模型的得分普遍上升,尽管它仍然偏好 gpt-4-0125-preview 超过自身。出人意料的是,它偏好多个开放模型(Mixtral、Yi、Starling)甚至 gpt-3.5-turbo 超过 gpt-4-0613。
表 3. GPT和Claude作为评判的排行榜比较
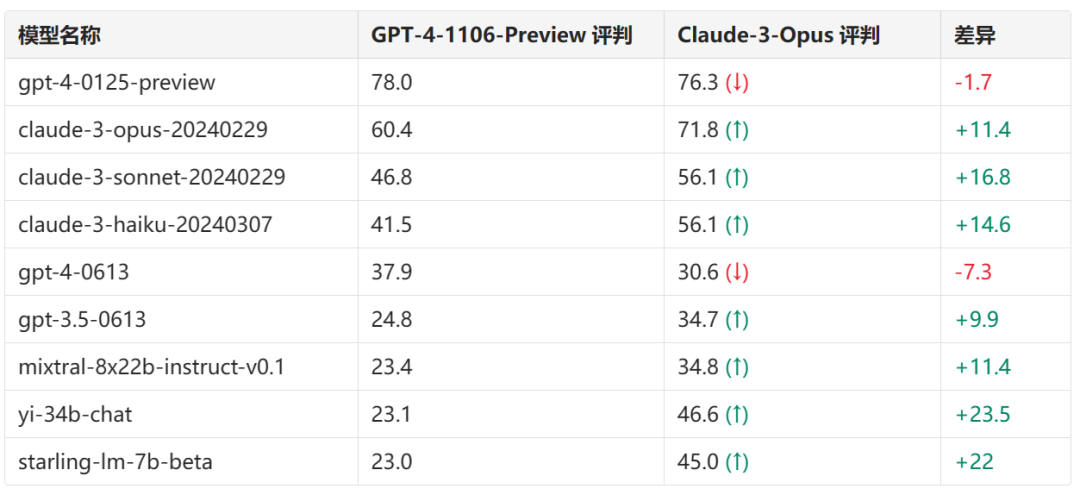
在此表格中,“↑”表示分数提高,而“↓”则表示分数降低。这些数据显示了不同AI模型在两种不同评判AI(GPT-4-1106-Preview和Claude-3-Opus)评分下的表现以及它们之间的差异。
我们进一步使用我们提出的分离性和一致性指标比较 GPT-4 和 Claude评委,并发现 GPT-4-Turbo 评委在所有指标上明显更好。
表 4:LLM评判与人类的统计比较
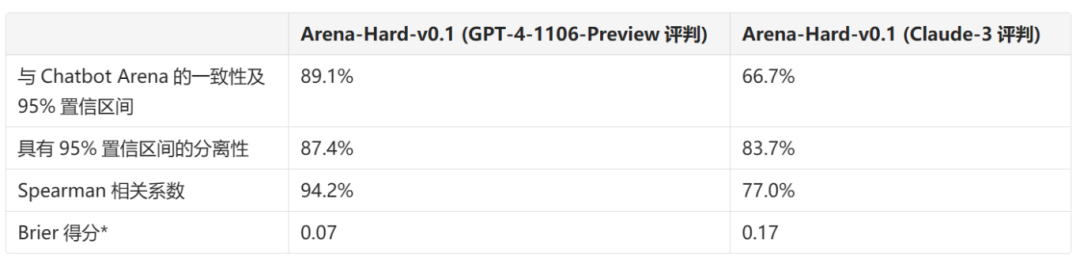
*Brier得分(数值越低越好),用于测量概率准确性的统计评分函数。(更多信息请见“将基准测试视为预测问题”部分)
我们手动比较了 GPT-4-Turbo 和 Claude 作为评委的不同判断示例。我们发现当两个评委不一致时,通常可以分为两个主要类别:
1.保守评分
2.提示的不同观点
我们发现 Claude-3-Opus 不太可能给出严格的分数——它特别不愿意宣布一个回应比另一个“显著更好”。相比之下,GPT-4-Turbo 将识别模型回应中导致错误答案的错误,并对模型进行显著更低的评分。
另一方面,Claude-3-Opus 有时会忽视较小的错误。即使 Claude-3-Opus 确实发现了这些错误,它也倾向于将它们视为次要问题,在评分时表现出宽容。这种效果在编程和数学问题中尤其明显,其中小错误更有可能完全破坏最终答案;这些评分仍然从 Claude-3-Opus 那里得到宽容,但 GPT-4-Turbo 则不会。有关不同判断的具体示例,请参见下面的附录,其中展示了许多这种现象。
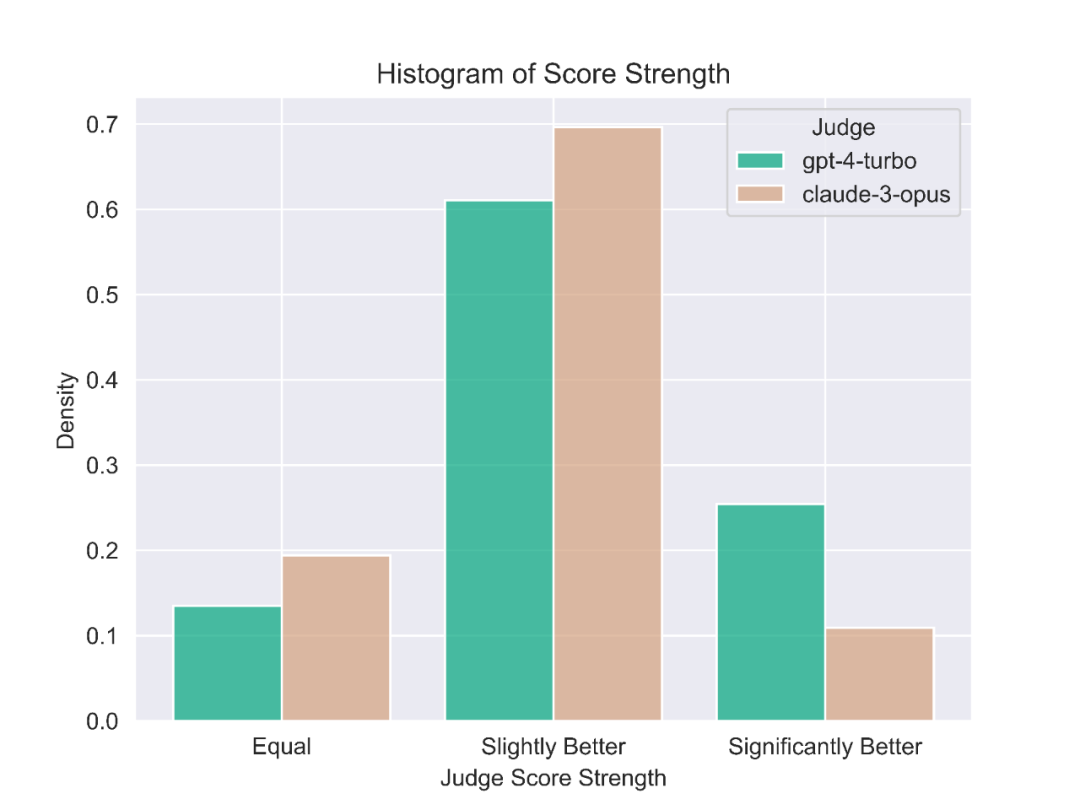
图 5:评分强度
还有一小部分提示,Claude-3-Opus 和 GPT-4-Turbo 的评委认为具有根本不同的观点。例如,在给定一个编程问题时,Claude-3-Opus 可能选择为用户提供最具教育价值的回应,提供简单的结构,而不依赖于外部库。
然而,GPT-4-Turbo 可能优先考虑提供最实用的答案,不管其对用户的教育价值如何。虽然这两种解释都是有效的评判标准,但我们发现 GPT-4-Turbo 的观点可能与平均用户更相关。
尽管观察到 Claude-3-Opus 和 GPT-4-Turbo 的判断风格存在差异,我们发现评委的整体软一致性率为 80%。两个判断“软一致”是指它们最多相差一位,换句话说它们不矛盾。
▊ 局限性
冗长性:LLM评委是否偏好更长的回应?
LLM作为评委时,已知存在对冗长回应的偏好问题(见长度控制的AlpacaEval)。下图比较了MT-Bench和Arena-Hard-v0.1中平均Token长度和分数。从视觉上看,并无明显的分数与长度之间的强相关性。
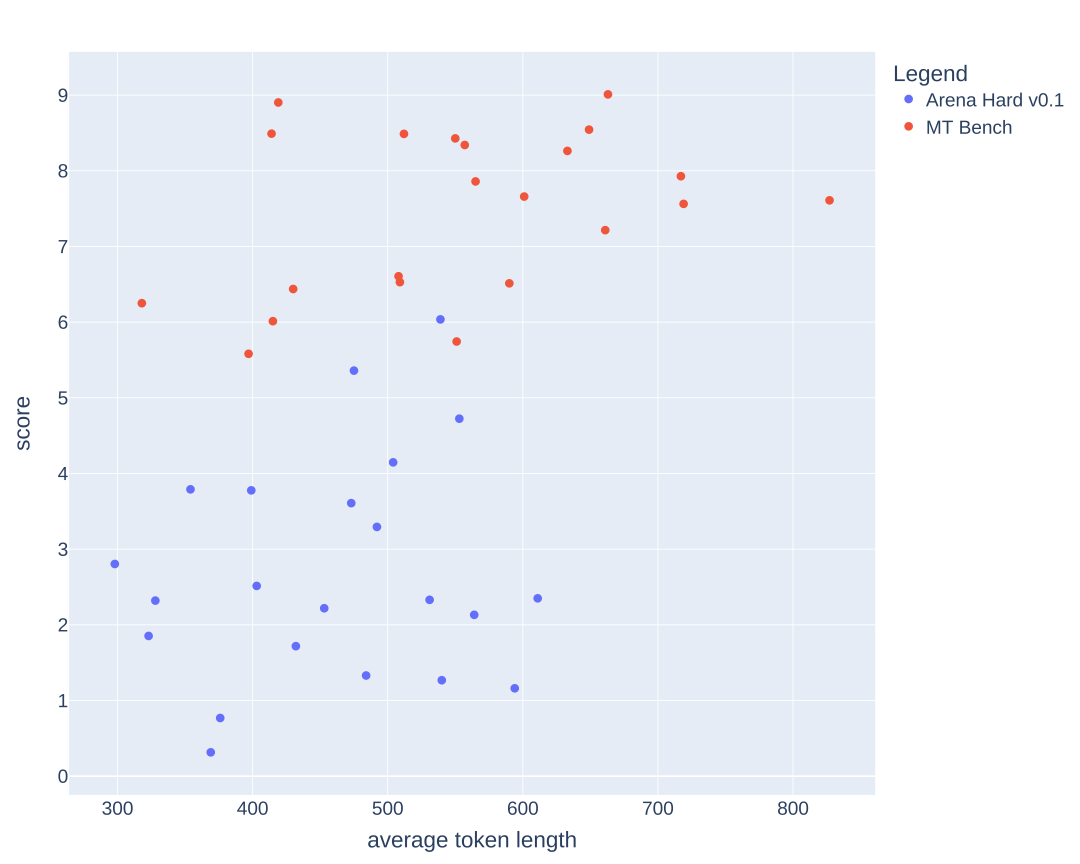
图 6:冗长性散点图,比较Arena-Hard-v0.1和MT Bench。
为进一步检验潜在的冗长偏见,我们对三种不同的系统提示(原始、健谈、详细)进行消融实验,使用GPT-3.5-Turbo。
观察结果表明,尽管输出平均#tokens较长,但GPT-4-Turbo和Claude-3-Opus作为评委可能会受到更长输出的影响,其中Claude在“更详细”的系统提示下受到的影响显著更大。GPT-3.5-Turbo在与GPT-4-0314的比较中胜率超过40%。
表 5. GPT与Claude作为评委的长度偏见比较
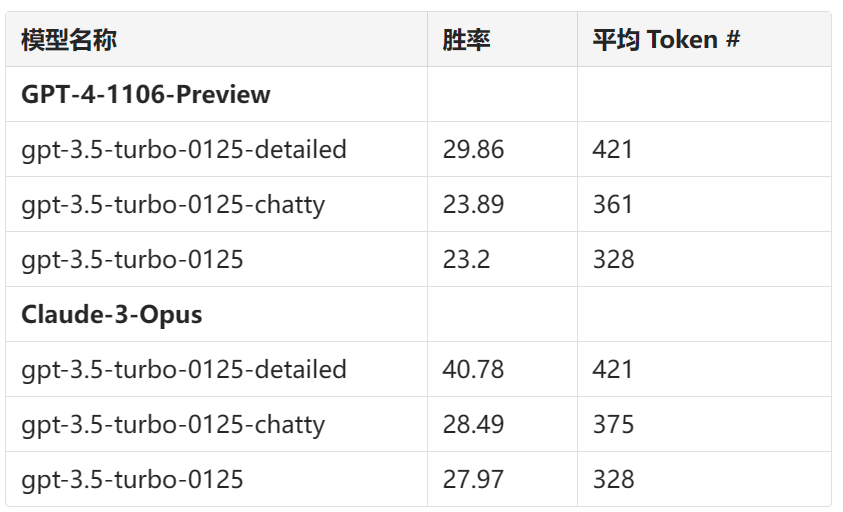
System Prompt:
detailed: “You are a helpful assistant who thoroughly explains things with as much detail as possible.”
chatty: “You are a helpful assistant who is chatty.”
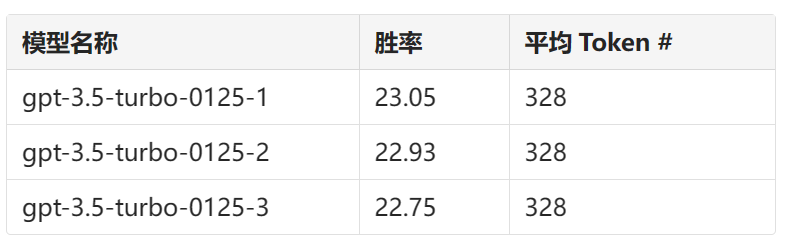
GPT-4 判断的变异性
我们发现即使在temperature=0的设置下,GPT-4-Turbo可能仍会生成略有不同的判断。这里,我们对gpt-3.5-turbo-0125进行了三次重复判断并报告其变异性。由于预算有限,我们只能评估所有模型一次。我们建议使用置信区间来确定模型分离。
@草木青解释:"temperature"是一个参数,它决定了生成文本的随机性。当temperature设置为0时,模型会倾向于选择最高概率的词汇,从而生成更确定、更一致的文本。然而,即使在temperature为0的情况下,由于模型内部的微小变化或者不同的初始条件,可能仍会产生一些差异。这意味着,即使在非常确定的设置下,AI的输出也可能会有轻微的变化。
表 6. Arena Hard v0.1的3次单独运行之间的变异性。
潜在的自我偏见和提示选择偏见
我们还观察到潜在的自我偏见,即LLM评委(如Claude评委)更偏好Claude的回答。此外,提示选择过程可能受LLM影响。基准测试也未能评估多轮互动。
将基准测试视为预测问题
我们尝试将置信度和相关性结合成一个标准化的基准测试指标。以下表格展示了与不同模型的Chatbot Arena整体得分的Brier得分相关性。
Brier得分与不同模型在Chatbot Arena总分的相关性

*20K人类偏好对决,从Chatbot Arena随机抽取的,涉及20个顶级模型。
模型开发者通常使用基准测试进行模型选择,而不是作为性能的地面验证。基准测试作为昂贵和复杂评估的便宜和轻量级替代品,因此我们期望基准测试能告诉我们作为模型开发者一些关于模型实际表现的置信区间。从这个意义上说,基准测试是真实长期表现的一种预测。
预测是置信度与不确定性之间的微妙平衡。因此,一个好的基准测试应该在明确不平等的模型之间显示出置信度,但在评估合理相似模型之间的排名差异时应展现出不确定性。我们可能只需要看看一个给定基准测试在分离模型对时有多置信。
一个好的基准测试不必总是对分离模型保持置信——你不希望你的基准测试在错误时过于自信。例如,假设有一对模型A和B,基准测试1和2。假设实际情况是模型A比B好。我们对基准测试1和2进行引导,并检索两个模型性能的置信区间。基准测试1自信地预测模型B比A好,而基准测试2以低置信度预测模型B比A好。在这种情况下,我们应该说基准测试2实际上比基准测试1更好地预测了这对模型。也就是说,只有在答案正确时,高置信度才应该得到奖励,而在答案错误时,低置信度更好。
在这个问题背景下,我们引入预测标准,简单地用二进制指标1表示某个模型对(和)。预测给出这个指标为真的概率。较高的概率预测表明更大的置信度认为1将是真的。我们可以使用引导的得分均值和方差生成这些概率预测,进而定义一个高斯分布。然后我们使用Chatbot Arena的Bradley Terry系数解析1的实际标签。
一个在期望中公平的预测损失是Brier Score。Brier分数奖励置信度,而对自信的错误进行惩罚。我们可以通过将每个模型对的基准测试预测的1与Chatbot Area地面得分进行比较来计算基准测试的预测性能。
在这里,我们假设Chatbot Arena作为“地面真相”,因为Alpaca 2.0 LC和Arena Hard都被宣传为Chatbot Arena评估流程的廉价替代品。我们将在未来的研究中进行相关性比较,届时我们将使用与给定基准测试相似的分布来计算Chatbot Arena的Bradley Terry系数。
我们发现Arena Hard平均预测损失更低,表明它在分数和置信度方面都更准确。
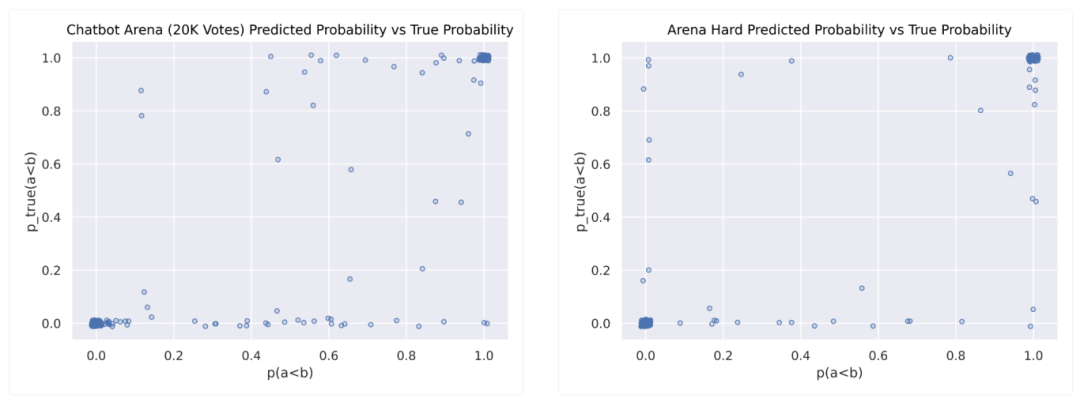
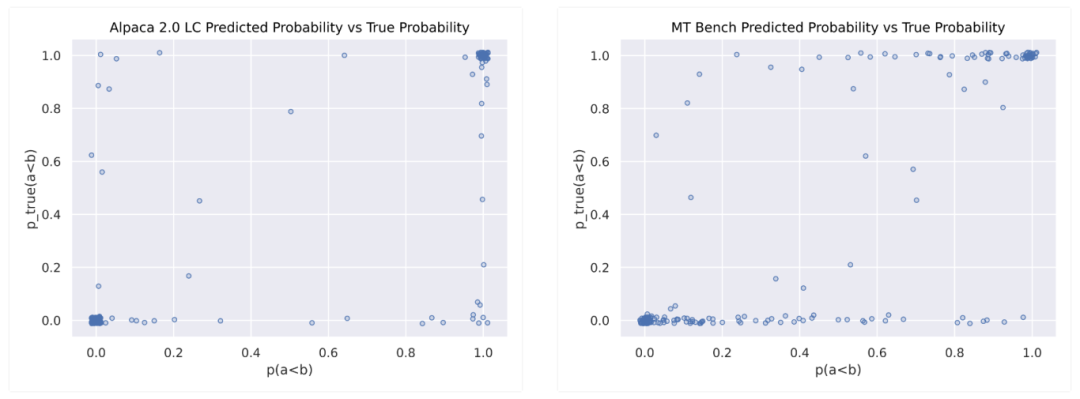
以上是模型预测概率与引导的Arena“地面真相”概率的比较(抖动以显示聚类)。Alpaca评估和Arena Hard都有围绕(0,0)和(1,1)的大聚类,表明良好的预测,而Arena Hard在(0,1)和(1,0)上的聚类更轻,如果有的话,显示出较少的过度自信。
MT Bench在顶部和底部有重尾,显示出过低的自信。然而,这些基准测试没有显示出一个“理想”的y=x曲线(带密集端点),这是与完美校准的预测期望的,表明未来研究有空间。
未来
我们希望在后续技术报告中更深入研究上述局限性和偏见。我们也正在深入研究统计数据,以研究如何衡量基准测试的质量。最后,我们也希望频繁更新Arena-Hard。所以期待频繁的新基准测试!
致谢
我们感谢Matei Zaharia, Yann Dubois, Anastasios Angelopoulos, Lianmin Zheng, Lewis Tunstall, Nathan Lambert, Xuechen Li, Naman Jain, Ying Sheng, Maarten Grootendorst的宝贵反馈。我们感谢Siyuan Zhuang和Dacheng Li对代码的宝贵审查和调试。我们感谢Microsoft AFMR提供Azure OpenAI信用支持。我们还感谢Together.ai & Anyscale提供开放模型端点支持。
引用
cssCopy code
`@misc{arenahard2024,
title = {From Live Data to High-Quality Benchmarks: The Arena-Hard Pipeline},
url = {https://lmsys.org/blog/2024-04-19-arena-hard/},
author = {Tianle Li*, Wei-Lin Chiang*, Evan Frick, Lisa Dunlap, Banghua Zhu, Joseph E. Gonzalez, Ion Stoica},
month = {April},
year = {2024}
}`
附录
附录图1:50个Arena Hard聚类的相似性热图
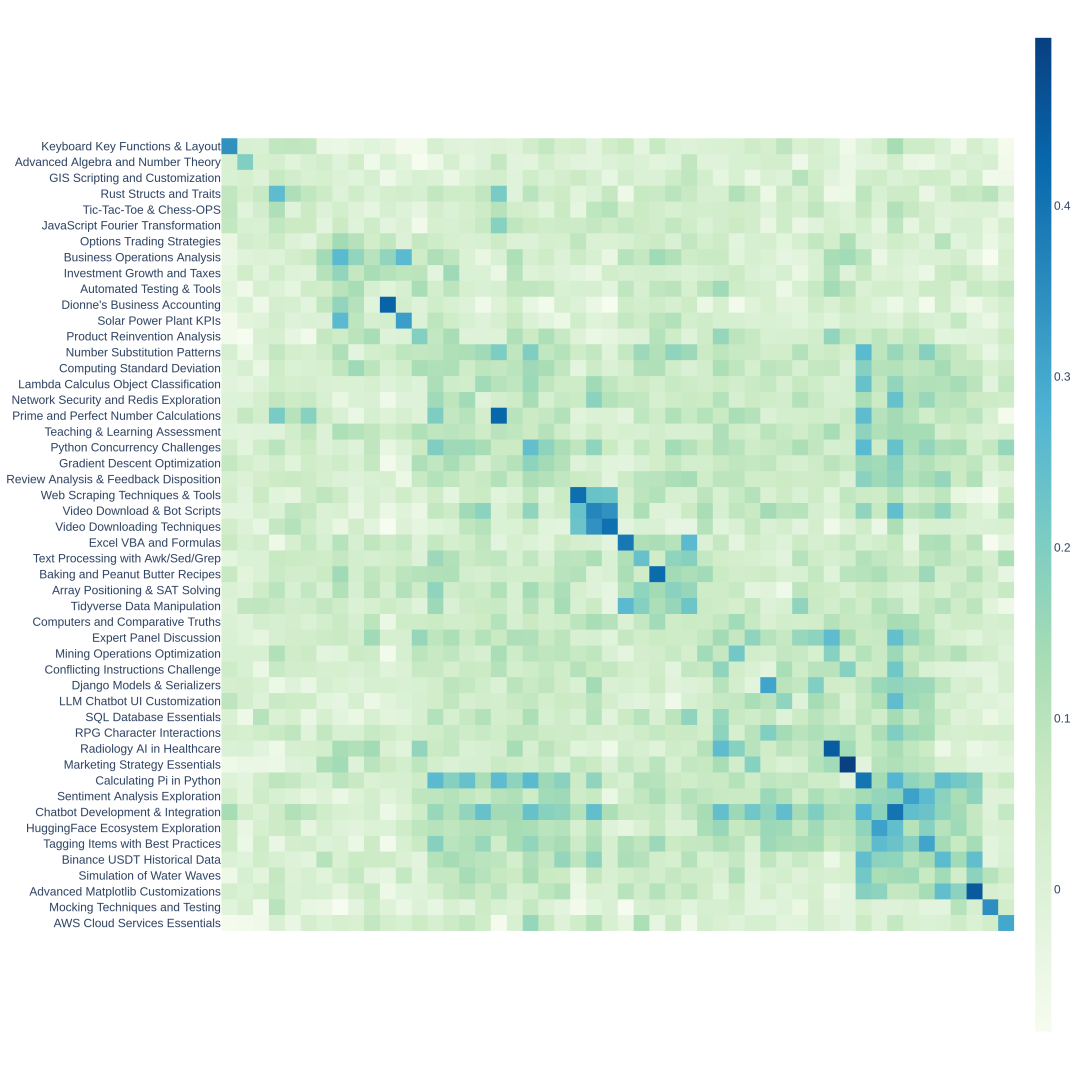
附录图2:在层次结构中可视化的前64个聚类。x轴表示余弦相似性距离。y轴显示每个聚类的主题标题,由gpt-4-turbo总结。
本文链接:https://ki4.cc/Claude/20.html
claudeai.aiclaude官网怎么登录claude ai官网地址claude官方网页版claude官网名字claude人工智能 官网claudeai官网claude官网旗舰店claude中国官网slack官网登录claude