OpenAI 的 GPT-4 似乎又变得懒惰了。不过,这一次,ChatGPT 付费服务模型的沮丧用户并没有等待快速修复。相反,他们正在寻找其他模型,其中有一个特别吸引了他们的注意力:Anthropic 的Claude。

最近几天,2023 年 3 月首次发布的 GPT-4 的用户一直在 OpenAI 的开发者论坛和社交媒体上发泄,该模型的能力似乎远不如以前。
有些人抱怨它没有遵循“显式指令”,在要求提供完整代码时提供了截断的代码。其他人则提到了该模型完全不响应他们查询的问题。
“现实是它已经变得无法使用,”一位用户上周在 OpenAI 在线论坛上写道。
让用户感到沮丧的是,这并不是第一次性能落后于另一个模型,该模型不仅本应是 OpenAI 最好的模型,而且是他们每月支付 20 美元才能使用的模型。
去年夏天已经出现了 GPT-4 变得越来越懒惰和愚蠢的迹象。该模型似乎遇到了麻烦,因为它表现出“逻辑减弱”,同时向用户返回了错误的响应。
今年早些时候,更多的懒惰证据再次出现,OpenAI 首席执行官 Sam Altman 甚至承认 GPT-4 很懒惰。他二月份在社交媒体上发帖称,已经发布了修复程序来解决投诉。
面对 GPT-4 的新一批问题,用户一直在尝试一系列其他模型,这些模型不仅与 OpenAI 的顶级模型相匹配,而且似乎也优于它。
以 Anthropic 的Claude为例。 OpenAI 的竞争对手在谷歌和亚马逊等公司的支持下,于本月初发布了 Claude 模型的高级版本,称为 Claude 3 Opus。将其视为 GPT-4 的等价物。
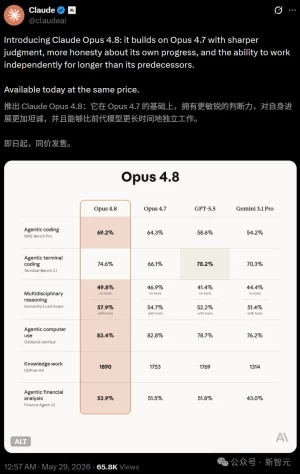
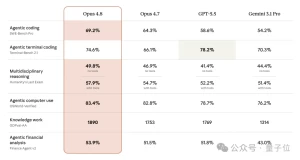
在发布时,Anthropic 分享了一些数据,将 Claude 3 Opus 的表现与同行在“本科水平知识”、“数学问题解决”、“代码”和“混合评估”等多个基准方面进行了比较。在几乎所有这些方面中,Claude都名列前茅。
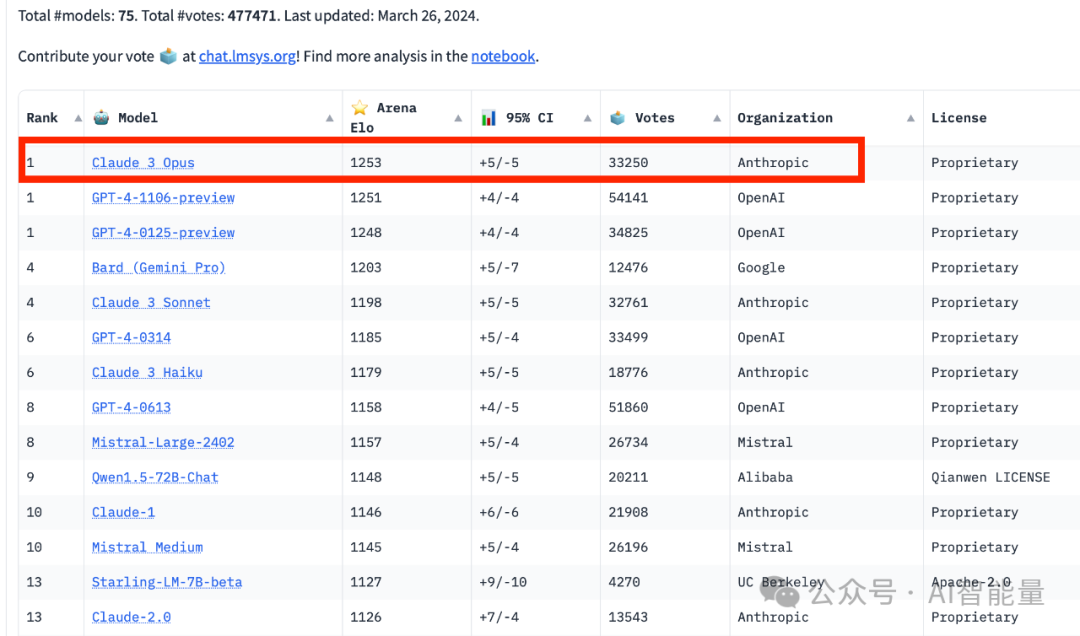
不仅仅是 Anthropic 的数据表明它的模型更好。本周,Claude 3 Opus 在评估 AI 模型的开放平台 LMSYS Chatbot Arena 上超越了 GPT-4。
在与 Claude 3 Opus 进行编码会议后,软件工程师 Anton 上周在 社交媒体上得出结论,它碾压了 GPT-4。 “我不认为标准基准能够公正地描述这个模型,”他写道。
天使投资人 Allie K. Miller 承认 GPT-4 感觉比几个月前更糟糕。 “我认识的大多数人都在使用 Claude 3,”她写道,还有 Mistral AI 的 Mixtral 8x7B 模型。